Most of what I've seen called "AI-assisted development" is just automating the edges of a human process. Smarter code review, better issue generation, failed pipeline automations.
That's not what I built. I built a software factory where no human is in the loop at all — and what surprised me wasn't how fast it is. It's how much simpler everything got once I stopped designing around people and all the controls, settings, and visibility they require.
Here's the loop:
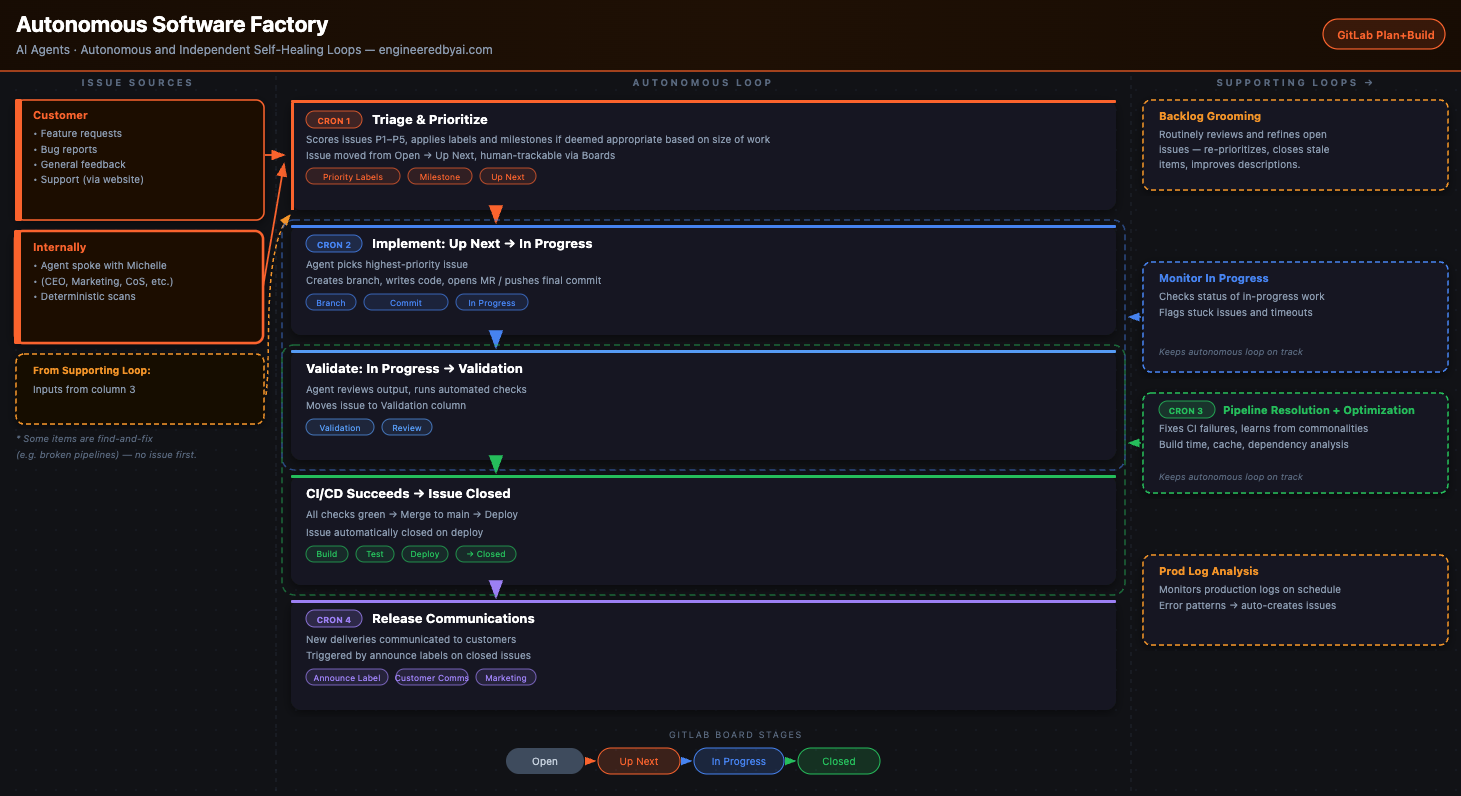
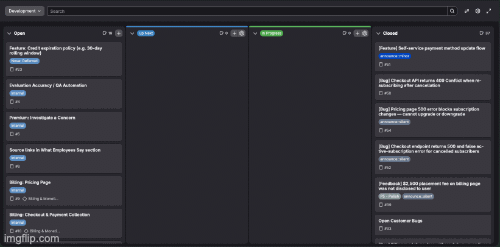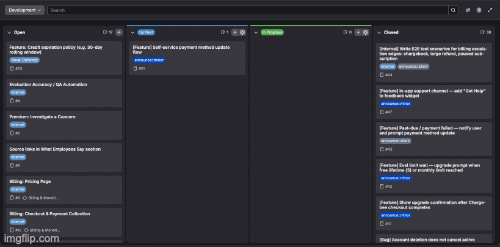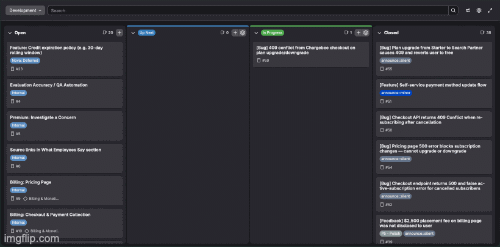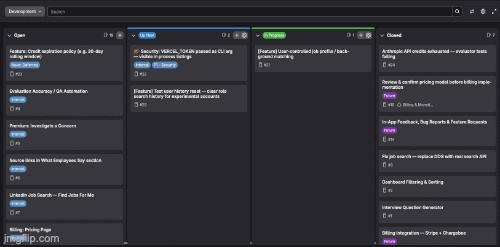
Issues Come In From Three Places
Customers submit them through a feedback form embedded on all pages of the site — feature requests, bug reports, general feedback, and support tickets all come through here. Internally, the issues may come from me or another agent mid-conversation. And the factory itself generates them — catching a user hitting the same error four times in two minutes in production and creating the issue automatically, before anyone reports anything.
A Triage Agent Prioritizes Everything
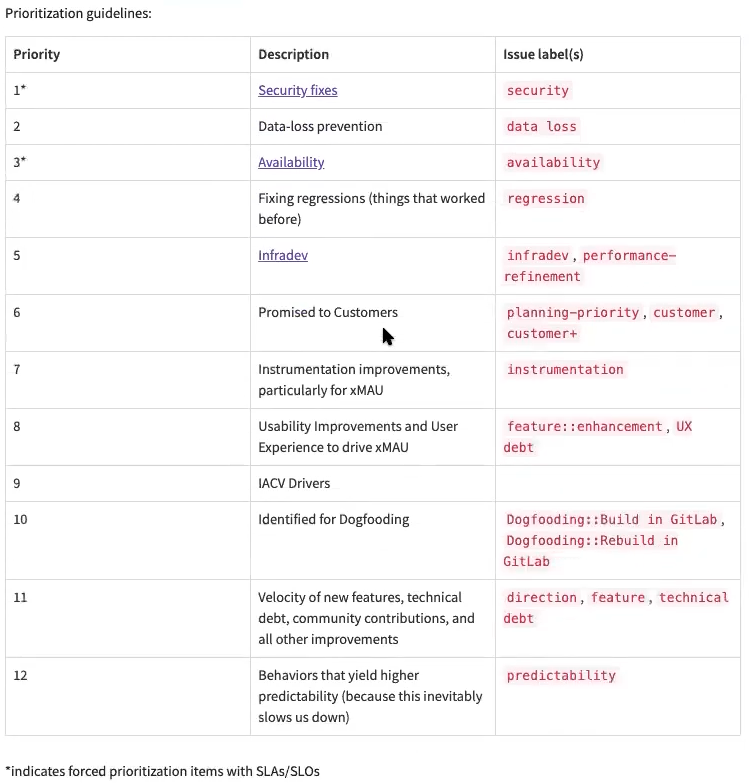
Technically this is the CEO agent, due to alignment with company goals. P1 is security — always first, no exceptions. Then high-severity bugs, then revenue impact, then features, then polish. Some things should "just work" (like a broken pipeline, misconfigured deployment, or the billing site going down) and don't even need triaged before they are picked up. No negotiations, sprint planning, or matrices of labels to score a priority with. It just runs.
I'll be honest: the prioritization matrix, which used to exist to resolve conflict between humans, matters a lot less than I expected. My P1–P5 version is not simplistic because it's a new project — it's simplistic because agents are fast enough that the cost of sequencing has basically disappeared. 15 billing workflows used to mean someone had to fight for calendar time, negotiate on priorities or scope or both, or barter for headcount to do the job. That was actually what "the system working" looked like — when 2 people walked away mildly annoyed. For my real-world use case, it took about three minutes in conjunction with some other high severity bugs. Yes, even despite the AI engineer estimating it would take 3 hours. Typical Engineering.
It's a deeper shift than it sounds like. A lot of engineering process exists to manage scarce engineering capacity. When that scarcity changes, the process has to change with it.
GitLab v1 Priorities
GitLab v2 Priorities
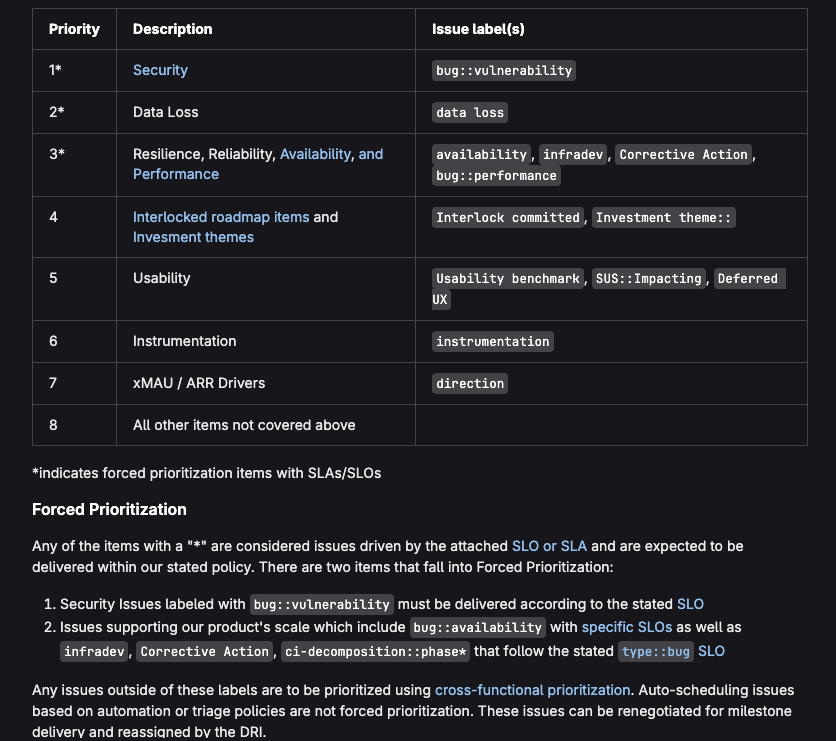
Autonomous Priorities →

An Implementation Agent Picks Up Whatever's Next
Before it starts something new, it checks on anything already in progress. If something's been running too long, it diagnoses why: stuck agents, missing context, ambiguous requirements, failed tool calls — and it self-heals the loop. The goal isn't to tell me something broke or is timing out, but to fix it and ensure the board always reflects real state and the autonomous loop is moving.
If everything previously In Progress was finished successfully, it picks up whatever got prioritized in the previous step — moves it to In Progress on the board, creates a branch, writes the code, and opens an MR or pushes the final commit. I have seen swathes of issues move from Up Next to In Progress to Closed upon each page refresh.
A Pipeline Loop Runs Constantly
This loop has two jobs in one. First, if a pipeline failed, it investigates — fixing CI failures, lint errors, type errors, and learning from commonalities so the same class of failure doesn't repeat. This shouldn't happen technically, because the work done in the previous step should pass the pipeline, but in case anything goes off-track, this step will remediate it.
Second, when the pipeline is running cleanly, it optimizes independently: deprecating old dependencies, cleaning up bloat, updating tooling, getting you faster build times. No one schedules that. It just happens when conditions are right.
Same loop, two modes, no human needed to investigate, prioritize, negotiate, or oversee things that should have worked right the first time. This loop facilitates Validation of the work done and Deployment of the same or future work, holding those steps accountable even when nothing breaks.
Once the Pipeline Succeeds and the Issue Closes
The work is assessed based on whether it was customer-facing or should be communicated externally, which a separate agent handles in its own closed loop. Production logs get pulled and analyzed automatically to understand how the work is performing in production. Error patterns create new issues that feed back into triage. The release communications loop fires based on labels added when the work was assessed for customer impact — features get announced, customers get updated, and any issues they may encounter when they try it out should be addressed before they get there. All triggered by the work that just closed. None of it something I think about.
Agents Are Better Than Alerts
After the deploy — having already monitored for crashes and routine production log analysis — my agents are looking for patterns that indicate a customer is experiencing friction. Silently, before they file a ticket.
The example that changed how I think about this: a customer hit the same error four times in two minutes in production. The log analysis agent caught it, created a GitLab issue with full context and its own assessment of severity, and labeled it. By the time that customer might have reached for the support form, the issue was already addressed. For this problem, there is fundamentally no way I would have been able to 1) see the error and determine how often it occurs or 2) understand that this is an alert I should set up — before the agent did.
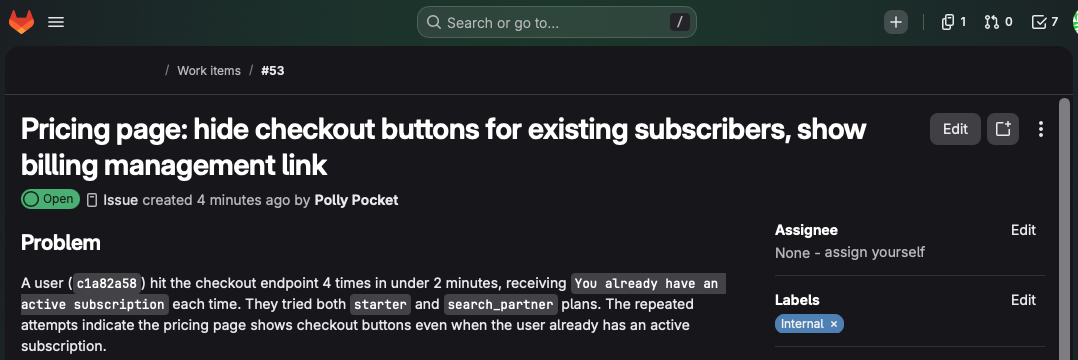
Alerts tell you something happened. They don't tell you what it means, they don't assess severity, they don't create the work item. A well-prompted agent does all three. And it doesn't page you at 2am for something that can wait until morning.
That issue feeds back into Triage. The loop closes.
There are four cron jobs that wake up an agent to do one of the things above. Each one a closed loop, but together — one continuous cycle. Whether relevant or not, it's human-trackable the whole way via GitLab boards: Open → Up Next → In Progress → Validation → Closed. I like having this because I'm eager to see my bug reports get resolved, but probably don't need it either.
What Stopped Mattering
I am amazed at how many ceremonies, functionalities, and processes stopped mattering. I knew it would be a lot, but I didn't think it would be this much.
Here are just a few of those things and the time returned back to the humans:
- Hours: On-call runbooks — production mostly self-heals before anyone's paged
- Weeks: Sprint planning — there's nothing to negotiate when triage is automated and velocity is measured in minutes. The cognitive overhead of tracking who's working on what is gone. Context-switching when something urgent lands mid-sprint is irrelevant.
- Months: Roadmapping — issues come in from all the important places, and we can trust they will ultimately be delivered if they are aligned to business goals
- Days: Handoff meetings — there are no handoffs. This would have included engineers passing work to other engineers due to OOO or other reasons, PMs drafting customer communications, explaining work to the engineering manager, or identifying a production issue and asking around to see if it's expected, who the right team is, and whether it can be prioritized
- Days: Dependency audits and upgrades as a scheduled human task — handled passively by the pipeline cron when it has nothing else to do
- Hours: Escalation paths — the loop corrects itself. No need to get status updates, go talk to a manager when work isn't moving fast enough, alert and route production incidents, or drop what you're doing for a customer support problem. Reactive firefighting and the "why wasn't this caught sooner" postmortem conversation is completely gone.
- Hours: Deployment coordination — the pipeline cron owns it, so engineers don't need to learn DevOps or work with the Release/Delivery team
- Hours: Release notes — generated from closed issue labels, based on what actually matters. Prevents overwhelming customers with auto-generated notes or overwhelming team members who need to curate more relevant customer communications.
- Years: "Who owns this?" — ownership is structural, not social. Have you ever had a Hot Potato domain at your company — one that no one has ever owned so it always seems to land on your team? Or a domain expert who resigns and takes the knowledge with them? These are problems that can last years at some companies when investment is hard to come by. In this model, they don't take up mental capacity at all.
The coordination overhead didn't feel optional when humans were in the loop. It just felt like part of the work you're responsible for. It wasn't. It's not.
I'm not saying every team should or can run like this, or even that it will last in production (though I have my optimistic hunch on that). There is a real risk: despite a resilient system, it can run itself off-track toward the wrong destination — creating a highly available and self-sustaining dumpster product. I intentionally excluded the Code Review process and the topic of Merge / Pull Requests until I have a need to implement that step. Direction still matters. Judgment still matters. I still set both.
But if you're trying to make your current process faster, you might be optimizing a human process that should actually be eliminated entirely.
The question worth asking isn't "how do we move faster?" It's "what would this look like if we designed it with no humans in the loop at all?"
The answer is usually simpler than you'd expect.